Our previous post touched upon a few basic topics for beginners in the crawling arena, but here it gets a bit more serious. So, let’s get going with spider configuration.
Here we present some useful configuration tips for Screaming Frog. It should facilitate the entire crawling process for those who do not not know where to start from, regardless of whether the target is a large or a small website.
Spider Configuration
We cover the following sections:
- Basic
- Limits
- Advanced
- Preferences
All four can be found under the Spider configuration menu and can be used to customise the crawling settings. They are all equally important as far as the analysis of large websites is concerned.
- Basic: This section either allows or disallows the spider crawling of certain items based on the type and the structure of different folders.
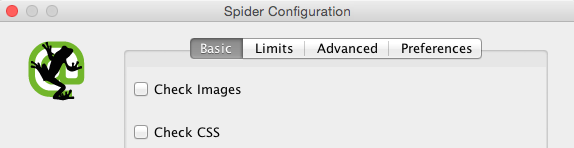
Among others, this section includes: Check Css (if disabled, the spider will just crawl html files); Check Java (if disabled, javascript won’t be crawled); Check SWF (if disabled, flash files won’t be crawled), and; Check External Links (if disabled, external links won’t be crawled).
- Limits: This section can limit the crawling based on selected parameters.
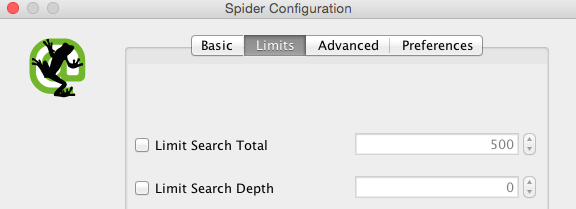
Among others, these are: Limit Search Total (it is a selection of the total number of urls crawled — the free version will automatically crawl up to 500 urls); Limit Search Depth (it is a selection of how many links away from your chosen starting point will be crawled), and; Limit Max Folder Depth (this is a selection that includes the total number of folders or sub directories set to be crawled).
- Advanced: These options are aimed at securing a deeper control of the URLs HTTP responses.
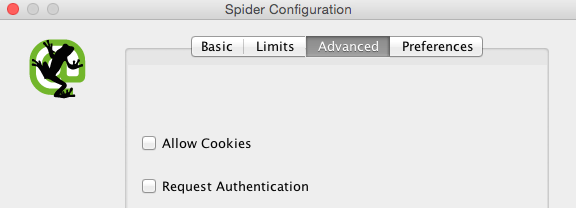
This section is particularly relevant when crawling large websites — its ‘Pause On High Memory Usage’ function lets the spider pause, displaying a “high memory usage” message when the crawl reaches a full memory allocation.
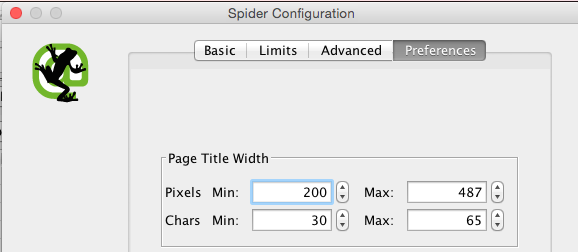
- Preferences: In this section is possible to enter manually certain parameters for characters and pixels guidelines for titles, meta descriptions, urls, H1, H2, images alt and so forth.
If you want this topic further with our team, please email us at info@hedgingbeta.com